序列模型
# 循环神经网络
全称 Recurrent Neural Networks, RNN,它可以应对多对多,多对一,一对一,一对多的任务,其模型可以表示为下图。
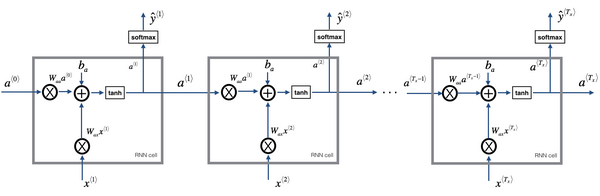
传统的 RNN 存在一个限制,某一时刻的预测仅使用了前面序列的信息,没有用到后面序列的信息,双向 RNN 可以解决这个问题(BRNN)。
此外,基本的 RNN 存在梯度消失的问题,而且很难捕捉到长期的依赖关系。
于是有了两个变体 GRU 和 LSTM。
# GRU 和 LSTM
GRU 只有两个门,是更加简单的模型,计算性能上更快,可以创建更大规模的网络。 LSTM 有三个门,更加强大和灵活,历史更加悠久。
# 深层 RNN
堆叠隐藏层,延迟对 y 的预测。
# 词嵌入
词嵌入(word embedding)是语言表示的一种方法,区别于 One-hot 表示,它可以让算法自动理解一些类似的词,比如男人对女人,国王对王后。
通过 t-SNE 算法可以将高维数据映射到平面中进行可视化。
一般情况下,自己的任务中数据集较小,需要使用迁移学习来优化性能,使用词嵌入进行迁移学习的流程如下:
- 从大量文本中学习词嵌入(或者下载预训练词嵌入模型)
- 迁移到只有少量标注数据的任务中来
- 此外,可以选择对词嵌入模型进行 finetune
词嵌入可以帮助我们进行类比推理,比如 男人 - 女人 = 国王 - ?,通过词嵌入,可以得到 ? = 王后。
那么如何得到有效的词嵌入呢?
# 学习词嵌入矩阵
词嵌入向量通常会被构造成词嵌入矩阵 ,每列为一个词向量 。
可以通过 与该词的 One-hot 编码 得到 ,即 。
通常以语言模型为载体进行词嵌入的学习,给定多个词预测一个目标词,让给定的词通过 转化为词向量,然后输入到神经网络(比如 Softmax 分类器)中预测目标词,进而优化词嵌入矩阵 。如下图所示(图片来自于 Andrew Ng)。
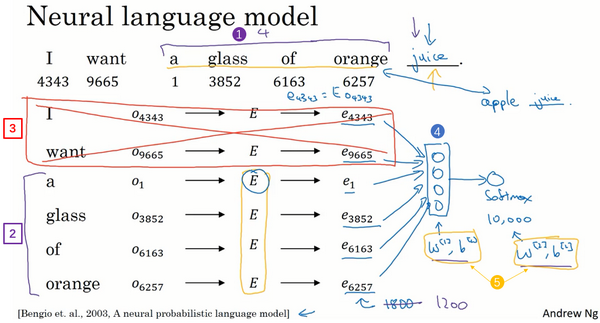
给定的多个词可以是目标词的上下文中的任意词,比如前 4 个,前后 4 个,前一个或者 5-邻域内任意一个词等。
# Word2Vec
Word2Vec 有两种很常见的方式:Skip-Gram 模型和连续词袋(CBOW)模型。
其主要还是基于前文的方法构建 Softmax 分类器,但是局限在于当 Softmax 类别多的时候计算速度很慢,因此想要扩大词汇表就更加困难了。
解决方案有两种:分级 Softmax 分类器和负采样。
- 分级
Softmax分类器将构建树状的二分类器,使得计算成本与词汇表的对数成正比 - 负采样则对每一对
上下文-目标词构建 个负样本,每次只训练 个二分类器,使得计算成本成为常数
此外,GloVe 算法也是一种计算词嵌入的方法。