注意力机制
# 1. 从 Seq2Seq 说起
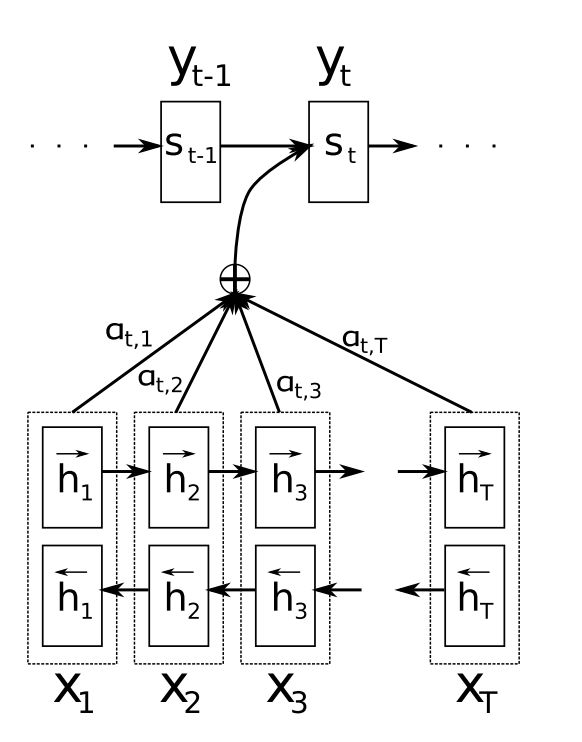
如果从源头来讲,注意力机制(Attention)最先是应用在 NLP 领域的机器翻译任务上的。 之前的机器翻译任务通常是 Seq2Seq 模型(Encoder-Decoder 结构)来解决的,Encoder 负责学习句子的表征, 将其总结为一个定长的向量(hidden vector),然后输入给 Decoder 来解码翻译,但注意只有第一个 Decoder 接收 hidden state, 之后的每个 Decoder 都将上一个 Decoder 的输出作为自己的输入。
但是这个结构有个问题,对于较长的句子,很难保证最后的 hidden vector 能够保留所有有效信息,因此翻译的效果也会显著下降。
为了解决由长序列到定长向量信息损失的问题,Attention 机制被引入了。Attention 机制的 motivation 来自于人类本身, 比如我们翻译句子的时候,往往只会关注翻译部分对应的上下文,同样 Attention 的思想也是给当前翻译词语的上下文更高的关注度。
这里的关键操作就是,在 Deocder 进行翻译的时候不仅仅依赖于最后一个 Encoder 的输出,它会依赖于每一个 Encoder 的输出,根据这些输出计算一个 Attention 分布, 然后用 Attention 对所有 Encoder 的输出做加权,从而得到 Decoder 的输入,也就是说,使用 Attention 可以打破原有的使用单一定长向量的限制, 使得模型关注到被翻译词语的上下文(也许距离当前词语很远)。
此外,通过可视化 Attention 矩阵,还可以更好地理解模型的工作机制。
说到这里,读者也许会不禁想问,Attention 这么牛,他到底是怎么算的?
# 2. 细说 Attention
要说 Attention,先看一张图。
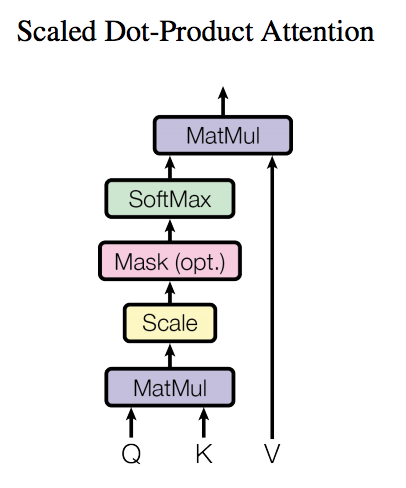
Attention 的计算通常有三个输入:Q(uery), K(ey), V(alue),这三个输入通过图中的一波操作,即可得到加权后的结果。
以上一节的 Seq2Seq 为例,Query 就是上一个 Decoder 的隐状态,Key 就是 Encoder 中的隐状态,Value 就是当前位置的 Encoder 的输出。
# 3. 何为 Self-Attention
此外,还有一种特殊的 Attention,Q, K, V 均来自于同一个输入,通过不同的线性变换矩阵转化得到,Transformer 中就用的是这样的方式。
关于 Self-Attention,这篇文章讲地非常棒,这里简单总结一下对于 Self-Attention 的求解过程:
- 计算 Attention score:计算当前 与每一个 的 Attention score(相似度),通常使用点积,即 。
- 归一化:为了梯度的稳定,对 进行归一化,即除以 。
- Softmax 激活:将归一化后的结果用 Softmax 激活成 Attention 分布。
- 加权求和:在得到 Attention 分布之后对每一个 进行加权,得到最终的表征向量。
向量化之后就可以表示为: